Basicamente, a filtragem de pacotes consiste em um conjunto de regras que analisam e filtram pacotes recebidos ou encaminhados por dispositivos de filtragem (Firewalls). A princípio, atua sobre as camadas 3 (rede) e 4 (transporte) do modelo OSI (Open System Interconnection), ou seja, analisando o cabeçalho de protocolos de rede (como IP ou IPX, por exemplo) e protocolos da camada de transporte (como TCP ou UDP).
Para compreender melhor o que são pacotes e como são encaminhados na rede:
No Linux, a infraestrutura responsável pela filtragem de pacotes é conhecida como netfilter. Ao contrário do que muitos imaginam, iptables (filtragem IP), arptables (filtragem ARP) e ebtables (filtragem MAC/bridge-firewall) consistem em ferramentas administrativas e oficiais que interagem com esta infraestrutura. Aliás, nos últimos anos, vem sofrendo alterações para dar lugar ao nftables, substituindo todas as demais ferramentas citadas anteriormente. Neste caso, dentre várias razões (como otimizações), trata-se de uma mudança bastante positiva, visto que a administração será centralizada e simplificada por uma única ferramenta, incluindo a filtragem IPv4 e IPv6 em um só lugar.
“Nas versões de kernel mais atuais (a partir da 3.13), o iptables já funciona em modo de compatibilidade. Portanto, sugiro que os administradores comecem buscar informações sobre o nftables o quanto antes – a substituição será uma questão de tempo. Mas, fiquem tranquilos, pois a essência do netfilter (lógica de tabelas e cadeias, por exemplo) se mantém“.
“Neste artigo de introdução, não abordaremos a utilização do nftables. O iptables ainda é a ferramenta mais utilizada e melhor documentada. Porém, ao longo do tempo, pretendo abordar o assunto no blog“.
O netfilter é uma implementação de “firewall com inspeção de estados” (capacidade de atuar sobre as camadas do protocolo TCP e identificar o estado de conexão). Mas, ao mesmo tempo, oferece flexibilidade suficiente para extrapolar este conceito, permitindo a integração com diferentes ferramentas em espaço de usuário ou mesmo controles internos de SO. É possível, por exemplo, filtrar o payload de consultas de DNS diretamente, sem trabalhar com um serviço específico. E, se integrado com um serviço de IPS (como Snort ou Suricata), é capaz de atuar como Firewall de Próxima Geração. A capacidade de programação é ilimitada. Ao longo do tempo, compartilharei vários exemplos.
Por se tratar de uma implementação de firewall baseada na “inspeção de estados” (capaz de detectar uma conexão inválida, nova, estabelecida, reincidente ou assegurada), o sistema mantém, em memória, uma área reservada para mapear conexões negociadas explicitamente pelo firewall (área conhecida como conntrack) e outra para validar conexões esperadas posteriormente ou reincidentes (conhecida como expected) – a área de memória principal e responsável por estes mapeamentos é conhecida como tabela de estados.
A cada nova requisição, o sistema realizará uma entrada na tabela de estados (conntrack), mapeando a solicitação como NEW (nova). Se não houver impedimento para a abertura de conexão, o mapeamento será atualizado para ESTABLISHED (estabelecido). O processo é automático, mesmo que o administrador não digite uma única regra – basta que o módulo nf_conntrack_ipv4 seja carregado. É o que torna o sistema capaz de inspecionar o estado de conexão. Graças a este recurso, podemos escrever regras de firewall prevendo apenas o sentido de conexão que desejamos controlar, pois, se o tráfego for autorizado, a resposta será tratada por uma regra global que tratará qualquer fluxo mapeado como ESTABLISHED.
Podemos consultar os mapeamentos na tabela de estados através da ferramenta conntrack:
– Para instalar no Ubuntu: apt-get install conntrack
root@XPSFw-8300:~# modprobe nf_conntrack_ipv4 root@XPSFw-8300:~# conntrack -L conntrack | head -5 conntrack v1.4.3 (conntrack-tools): 160 flow entries have been shown. tcp 6 431995 ESTABLISHED src=10.1.1.182 dst=13.58.146.100 sport=33222 dport=443 src=13.58.146.100 dst=10.1.1.182 sport=443 dport=33222 [ASSURED] mark=0 use=1 udp 17 87 src=127.0.0.1 dst=127.0.1.1 sport=47371 dport=53 src=127.0.1.1 dst=127.0.0.1 sport=53 dport=47371 [ASSURED] mark=0 use=1 udp 17 96 src=127.0.0.1 dst=127.0.1.1 sport=59107 dport=53 src=127.0.1.1 dst=127.0.0.1 sport=53 dport=59107 [ASSURED] mark=0 use=1 tcp 6 431990 ESTABLISHED src=10.1.1.182 dst=216.58.202.202 sport=42944 dport=80 src=216.58.202.202 dst=10.1.1.182 sport=80 dport=42944 [ASSURED] mark=0 use=1 udp 17 96 src=127.0.0.1 dst=127.0.1.1 sport=52024 dport=53 src=127.0.1.1 dst=127.0.0.1 sport=53 dport=52024 [ASSURED] mark=0 use=1
Também é possível obter informações referentes ao número de entradas na tabela de estados:
– Número corrente de entradas:
cat /proc/sys/net/netfilter/nf_conntrack_count– Número máximo de entradas:
cat /proc/sys/net/netfilter/nf_conntrack_max
Há diferentes estados de conexão, os mais conhecidos e inspecionados são: “INVALID, NEW, ESTABLISHED e RELATED“. O INVALID costuma ser utilizado para impedir tráfego não esperado, como solicitações de conexão TCP sem o bit SYN ativo. Também podemos impedir explicitamente, filtrando o estado NEW, a abertura de conexão originada por interfaces WAN. O estado RELATED é bastante semelhante ao ESTABLISHED, a diferença é que ele trata conexões esperadas posteriormente e negociadas dinamicamente por protocolos específicos, como FTP e SIP (por exemplo).
Para entender a essência de filtragem, começaremos pela lógica de cadeias (chains):
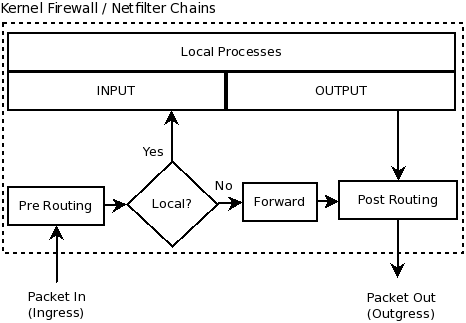
Imagem extraída do portal http://cooker.wbitt.com/index.php/IPTables
Cada cadeia (chain) é responsável por um fluxo específico:
1. Ao receber um pacote, antes de identificar o destino final, o sistema operacional primeiro avalia a cadeia PREROUTING (pré-roteamento). Ou seja, podemos filtrar qualquer pacote recebido (ingress). É neste momento que podemos interferir nas decisões de roteamento. Por esta razão, tanto o redirecionamento de conexão (NAT de destino) como a manipulação de roteamento por regra de firewall são feitos na PREROUTING.
2. A cadeia INPUT será verificada APENAS quando o destino de conexão for o próprio firewall – para disponibilizar o acesso aos serviços providos localmente. Do contrário, o sistema entende que o pacote deve ser encaminhado a outro roteador e, sendo assim, avalia as permissões definidas na FORWARD. Logo, na maioria das vezes, o controle de Internet é feito na FORWARD. Já a cadeia OUTPUT é processada quando o firewall for origem de conexão ou em resposta a um serviço consumido localmente (em seguida ao INPUT). Na maioria das vezes, a cadeia OUTPUT não é restritiva.
3. Por fim, antes de encaminhar o pacote ao endereço de destino, o sistema avalia a cadeia POSTROUTING (pós-roteamento). Neste momento a decisão de roteamento já foi concluída – o caminho de roteamento, bem como sua respectiva interface rede, já foi selecionado. Ou seja, podemos filtrar qualquer pacote que saia do firewall (egress). Por esta razão, o NAT de saída (seja SNAT ou MASQUERADE) é feito na POSTROUTING.
Este entendimento é essencial para qualquer configuração que envolva o netfilter.
Compreendido o papel das cadeias internas, o próximo passo é entender como aplicá-las de acordo com o objetivo do filtro: “filtragem de pacotes, NAT ou manipulação de pacotes (ou tabela de estados)“.
Internamente, o sistema separa o tipo de filtragem por tabela (função/objetivo):
| Tipo | Função/Objetivo |
| filter | Controle de acesso |
| nat | Tradução IP (NAT) |
| mangle | Alteração na tabela de estados ou cabeçalho IP |
| raw | Depuração (TRACE) ou controle de entradas na tabela de estados |
Vale lembrar que as regras são processadas por tabela, dentro de sua respectiva cadeia.
O fluxo, descrito anteriormente, por cadeia, permanece o mesmo seja qual for a tabela (caso a cadeia esteja disponível), mas existe precedência de processamento. Na prática, o importante é compreender a função de cada tabela (table) e a avaliação do pacote por cadeia (chain). Em outras palavras, memorize a primeira imagem exibida, que demonstra o fluxograma de cadeias do netfilter.
A título de curiosidade, a hierarquia completa entre tabelas e cadeias é a seguinte:
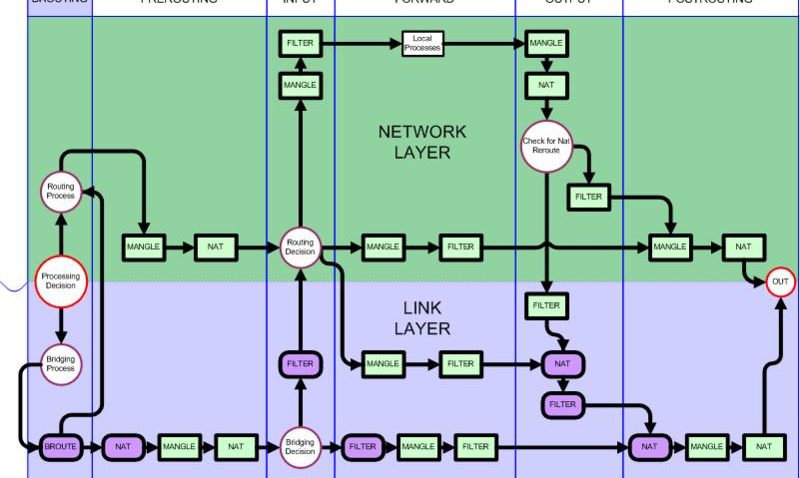
Imagem extraída da wikipedia
No iptables, elas podem ser identificadas com a opção “-t” (filter é a tabela padrão):
iptables -t filter ... iptables -t nat ... iptables -t mangle ...
O veredito (ação) de uma regra, que define qual critério de acesso será aplicado ao pacote, é conhecido como alvo (TARGET).
Em sua respectiva cadeia, o processamento das regras é top-down (em ordem ascendente – a partir da primeira linha) e, na maioria das vezes (poucos alvos não são decisivos), com o veredito final baseado na primeira condição satisfeita. A definição das regras requer uma atenção especial, pois a sequência de carregamento influenciará no resultado final.
Para controle de acesso, os alvos ACCEPT (aceitar), DROP (descartar) e REJECT (rejeitar) são os mais comuns. São decisivos, pois, ao satisfazer a primeira condição, interrompe-se a análise e o veredito final é aplicado.
Conforme exposto, o bloqueio pode ser feito com DROP ou REJECT. A diferença entre os dois é a possibilidade descartar um pacote silenciosamente ou não. Ou seja, com ou sem resposta. Com DROP, podemos evitar que o firewall envie respostas de ICMP Unreachable ou TCP Reset para cada requisição indesejada.
Diante de um syn-flood, por exemplo, a resposta do firewall tende potencializar o efeito do ataque, tornando o fluxo de pacotes mais intenso e, com isto, ampliando significativamente a demanda por CPU. Por outro lado, o descarte silencioso (DROP) faz com que os timeouts de conexão sejam processados de acordo com o socket e protocolo em questão, diminuindo a frequência de pacotes.
Por esta razão, em um firewall restritivo (default DROP), a política padrão (-P) costuma ser DROP.
iptables -P INPUT DROP iptables -P FORWARD DROP iptables -P OUTPUT ACCEPT
A política de acesso estabelecerá a permissão padrão caso nenhuma condição seja satisfeita pelo set de regras da cadeia em questão. Caso todo o tráfego de entrada seja restritivo, é perfeitamente aceitável tornar a cadeia OUTPUT permissiva.
“Existem casos específicos, como o controle de compartilhamento do Windows entre matriz e filial, em que devemos optar pelo REJECT preferencialmente (com a opção –reject-with tcp-reset). Do contrário, algumas aplicações, como o próprio Windows Explorer, ficariam congeladas até que ocorra timeout – a experiência do usuário seria bastante negativa“.
Na definição das regras, os alvos podem ser identificados com a opção “-j“:
iptables -A INPUT -i lo -j ACCEPT iptables -A FORWARD -p udp --dport 53 -j ACCEPT iptables -A FORWARD -m multiport -p tcp --dport 135:139,445 -j REJECT --reject-with tcp-reset
O objetivo foi demonstrar a essência de filtragem do netfilter, não a sintaxe de configuração propriamente dita. Uma vez que o administrador compreenda todos os fluxos envolvidos, a sintaxe de configuração pode ser consultada em diferentes fontes, inclusive em nosso blog. Não há mistério.
Para finalizar, demonstraremos uma configuração simples o suficiente para proteger os serviços disponíveis em um equipamento de firewall ou desktop pessoal. Neste caso, como desejamos controlar o acesso remoto aos “serviços locais”, escreveremos regras de INPUT na tabela filter.
Por exemplo:
iptables -P INPUT DROP iptables -A INPUT -i lo -j ACCEPT iptables -A INPUT -i eth0 -s 10.0.0.0/24 -p tcp --dport 22 -j ACCEPT iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT iptables -A INPUT -j DROP
Por ser padrão, omitimos a identificação da tabela filter. É evidente que, na definição de regras de NAT ou classificação de pacotes (QoS), não será possível omitir.
É comum encontrar questionamentos quanto a posição da regra que valida o “estado de conexão” (–ctstate ESTABLISHED,RELATED). Alguns administradores posicionam no início, antecedendo as demais regras. Particularmente, é uma abordagem que não me agrada muito e procuro evitar. O motivo é simples: “dependendo do set de regras, o número de comparações será muito menor do que uma consulta na tabela de estados (muitas vezes desnecessária)“. Ao longo do tempo, o número de conexões mapeadas pode subir consideravelmente.
Por padrão, cada conexão TCP ociosa pode ser mantida até 5 dias na tabela de estados:
sysctl net.netfilter.nf_conntrack_tcp_timeout_established